So baust du dein eigenes ChatGPT-Backend mit NestJS und OpenAI
Eigene API statt Vendor-UI. Viele nutzen ChatGPT über die offizielle Weboberfläche von OpenAI, doch wie wäre es, die KI in die eigene Anwendung einzubinden? In diesem Tutorial zeige ich dir Schritt für Schritt, wie du mit NestJS (einem Node.js-Framework) und der OpenAI-API dein eigenes ChatGPT-Backend baust. Statt nur die Vendor-UI zu verwenden, erstellst du eine eigene API als Gateway zu ChatGPT. Keine Sorge, auch wenn du wenig Erfahrung mit TypeScript hast. Wir gehen alles für Einsteiger verständlich durch. Am Ende hast du einen funktionsfähigen Server, der Anfragen entgegennimmt, an OpenAI weiterleitet und die Antworten an deinen Client streamt, komplett mit Authentifizierung, Logging, Tests und Deployment. Los geht’s!
Architekturüberblick (Gateway, Rate Limits, Logging)
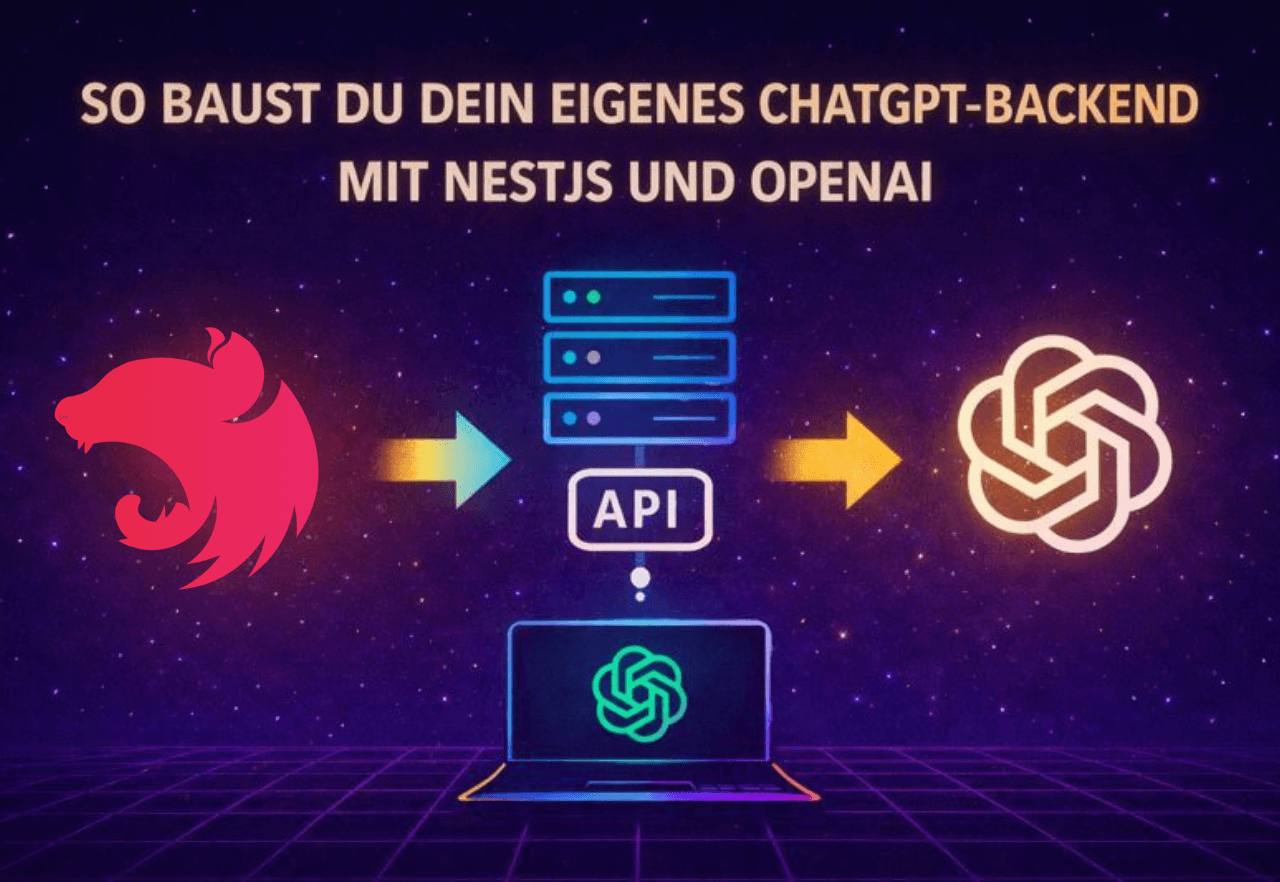
Bevor wir in den Code eintauchen, betrachten wir die Architektur. Unser NestJS-Backend fungiert als Gateway zwischen Client und OpenAI. Das heißt, deine Anwendung (sei es eine Web-App, Mobile-App oder ein anderer Client) schickt Anfragen an dein NestJS-API-Backend, anstatt direkt an ChatGPT. Der Ablauf sieht vereinfacht so aus:
Client → NestJS Backend: Der Client sendet eine Anfrage mit einer Nutzer-Eingabe (Prompt) an einen Endpoint deines NestJS-Servers, z.B. POST /chat.
NestJS Backend → OpenAI: Dein Backend empfängt die Anfrage im Controller und nutzt einen Service, um die OpenAI API (ChatGPT) aufzurufen. Die Anfrage an OpenAI enthält den Prompt und evtl. weitere Parameter (Modell, maximale Tokens, usw.).
OpenAI → NestJS Backend: Die OpenAI-API generiert eine Antwort und schickt sie zurück an dein Backend.
NestJS Backend → Client: Dein Backend verarbeitet die Antwort (z.B. extrahiert den AI-Text) und gibt sie als HTTP-Antwort an den Client zurück. Optional kann hier Streaming eingesetzt werden, damit der Client die Antwort tokenweise erhält, während sie generiert wird.
Warum dieser Umweg über ein eigenes Backend? Dadurch hast du volle Kontrolle: Du kannst Rate Limiting einbauen, um zu verhindern, dass Benutzer oder Bugs zu viele Anfragen pro Minute schicken und dein OpenAI-Kontingent sprengen. Du kannst Logging hinzufügen, um mitzuverfolgen, welche Prompts gestellt wurden und wie lange die Antworten dauern und das hilft beim Debugging und Monitoring. Außerdem ermöglicht ein eigenes Backend zusätzliche Logik einzufügen, z.B. Post-Processing der AI-Antworten, Caching häufiger Antworten oder auch Filter, um unerwünschte Inhalte auszublenden.
Zusammengefasst bildet NestJS das stabile Fundament, um einen skalierbaren, sicheren API-Server bereitzustellen. In den nächsten Abschnitten richten wir das NestJS-Projekt ein und fügen Schritt für Schritt die gewünschten Features hinzu.
NestJS Setup (Module, Controller, Service)
Als erstes richten wir ein neues NestJS-Projekt ein und erstellen die grundlegenden Bausteine Module, Controller und Service für unsere ChatGPT-Integration.
Projekt erstellen: Falls noch nicht geschehen, installiere zunächst das NestJS-CLI (Command Line Interface) mit folgendem Befehl in deinem Terminal:npm install -g @nestjs/cli
Dann erstelle ein neues Projekt, z.B. mit dem Namen chatgpt-backend:
nest new chatgpt-backendFolge den CLI-Anweisungen (für das Beispiel wählen wir npm als Paketmanager). Anschließend kannst du ins Projektverzeichnis wechseln:
cd chatgpt-backendDas NestJS-CLI hat ein Grundgerüst angelegt. Schau dir kurz die Struktur an: Im Ordner src/ findest du unter anderem app.module.ts (Root Module) und app.controller.ts/app.service.ts (ein Beispiel-Controller und -Service). Für unser ChatGPT-Backend erstellen wir nun einen eigenen Modul-Bereich, z.B. ChatModule mit einem ChatService und ChatController (du kannst es auch OpenAIModule/OpenAIService nennen – wir bleiben hier bei Chat für die Verständlichkeit).
Benötigte Pakete installieren: Wir werden die OpenAI API ansprechen, wofür es ein offizielles Node.js SDK gibt. Installiere das OpenAI-Paket in deinem Projekt:
npm install openaiAußerdem ist es sinnvoll, das Config-Modul von NestJS zu nutzen, um Umgebungsvariablen wie den API-Schlüssel zu laden:
npm install @nestjs/configNun können wir unser Chat-Modul einrichten:
ChatService: Der Service kümmert sich um die Kommunikation mit OpenAI. Hier werden wir den API-Key laden und eine Anfrage an den ChatGPT Endpoint senden.
ChatController: Der Controller stellt eine HTTP-Schnittstelle bereit (z.B. POST /chat), nimmt Nutzer-Eingaben entgegen und gibt die Antwort zurück. Er ruft dafür den ChatService auf.
Erstelle zunächst das Modul und die Dateien. Mit dem NestJS-CLI geht das bequem:
nest g module chat
nest g service chat
nest g controller chatDieser Befehl erzeugt chat.module.ts, chat.service.ts und chat.controller.ts unter src/chat/. Nest registriert den Service automatisch im Module.
ChatService implementieren: Öffne die Datei src/chat/chat.service.ts. Wir importieren das OpenAI SDK und konfigurieren es mit unserem API-Schlüssel. Am besten legen wir den Schlüssel in einer Umgebungsvariable ab (z.B. in einer .env-Datei im Projektroot):
# .env
OPENAI_API_KEY=dein-openai-api-keyBinde das ConfigModule in app.module.ts ein, damit .env gelesen wird:
import { ConfigModule } from '@nestjs/config';
@Module({
imports: [ConfigModule.forRoot({ isGlobal: true }), ChatModule /* ... */],
// ...
})
export class AppModule {}Mit isGlobal: true steht das ConfigModule überall zur Verfügung, ohne es in jedem Modul erneut importieren zu müssen.
Nun zum ChatService (TypeScript-Code, aber wir erklären ihn Schritt für Schritt):
// src/chat/chat.service.ts
import { Injectable } from '@nestjs/common';
import { ConfigService } from '@nestjs/config';
import { Configuration, OpenAIApi } from 'openai';
@Injectable()
export class ChatService {
private openai: OpenAI;
constructor() {
// OpenAI initialisieren mit API-Key aus den Umgebungsvariablen
const apiKey = process.env.OPENAI_API_KEY;
this.openai = new OpenAI({ apiKey });
}
async generateAnswer(prompt: string): Promise<string> {
// Anfrage an OpenAI senden (ChatCompletion)
const response = await this.openai.responses.create({
model: 'gpt-5-nano',
input: prompt,
});
return response.output_text || 'No answer';
}
}Schauen wir uns das an: Im Konstruktor (constructor(private configService: ConfigService)) laden wir den API-Key über ConfigService. Dann erstellen wir ein OpenAIApi-Objekt (Teil des SDK), mit dem wir Anfragen stellen können. Die Methode generateAnswer nimmt einen Prompt (den Nutzertext) und ruft this.openai.responses.create auf, was dem ChatGPT-API-Aufruf entspricht. Wir spezifizieren das Modell (hier gpt-5-nano), und übergeben die Nachricht des Users. Die API antwortet mit einem Resultat, aus dem wir den Antwort-Text output_text entnehmen. Diesen geben wir zurück. (Hinweis: Hier vereinfachen wir und ignorieren Mehrfach-Antworten. Für einen einfachen Chatbot reicht das.)
ChatController implementieren: Öffne src/chat/chat.controller.ts. Wir definieren hier einen Endpoint, z.B. POST /chat, der eine Anfrage entgegennimmt. Über den Body der Anfrage soll der Prompt des Nutzers kommen (als JSON { "prompt": "Hallo, wie geht's?" }). Wir rufen dann den ChatService an und senden seine Antwort zurück.
// src/chat/chat.controller.ts
import { Controller, Post, Body } from '@nestjs/common';
import { ChatService } from './chat.service';
@Controller('chat')
export class ChatController {
constructor(private readonly chatService: ChatService) {}
@Post()
async createChat(@Body('prompt') prompt: string) {
const answer = await this.chatService.generateAnswer(prompt);
return { answer };
}
}Dieser einfache Controller hat einen POST-Handler ohne zusätzlichen Schutz (um Auth kümmern wir uns gleich). Er erwartet im Request-Body ein Feld prompt (NestJS kann einzelne Felder via @Body('prompt') direkt extrahieren). Er ruft dann chatService.generateAnswer(prompt) auf und gibt das Ergebnis als JSON zurück, z.B. { "answer": "Mir geht es gut, danke der Nachfrage!" }.
Jetzt haben wir schon das Grundgerüst unseres Backends: Ein Client kann eine POST-Anfrage an /chat schicken mit dem gewünschten Prompt und erhält die KI-Antwort zurück. Bevor wir das ausprobieren, kümmern wir uns noch um die Absicherung und einige wichtige Features.
Auth (API Keys/JWT), Config & Secrets
Da unsere API letztlich Zugriff auf deinen OpenAI-Key hat und potenziell Kosten verursachen kann, sollten wir sie nicht offen im Internet zugänglich lassen. Es gibt zwei gängige Ansätze, um Authentifizierung (Auth) einzubauen:
API-Schlüssel für Clients: Du könntest einen eigenen API-Key vergeben, den der Client mit jeder Anfrage mitschicken muss (z.B. als Header x-api-key: <geheimer Key>). Dein NestJS-Server prüft dann diesen Schlüssel bei jeder Anfrage.
JWT (JSON Web Tokens): Falls du ein Benutzer-Management hast, könntest du Benutzer login lassen und ihnen JWTs ausstellen. Die Chat-Endpoint wäre dann durch einen JWT-Guard geschützt und nur mit gültigem Token erhält man Zugriff.
Für ein einfaches Szenario reicht oft ersteres, nämlich ein statischer Schlüssel. Da dieses Tutorial für Einsteiger ist, skizzieren wir kurz beide Möglichkeiten:
API-Key Guard (einfach): Definiere in deiner .env einen geheimen Key, z.B. API_KEY=mein-tutorial-key. Schreibe einen einfachen Guard (eine Klasse, die NestJS’ CanActivate implementiert) oder einen Middleware, der pro Anfrage einen bestimmten Header prüft. Beispiel als Middleware:
// src/auth/apikey.middleware.ts (als Beispiel)
import { Injectable, NestMiddleware, UnauthorizedException } from '@nestjs/common';
import { Request, Response, NextFunction } from 'express';
@Injectable()
export class ApiKeyMiddleware implements NestMiddleware {
use(req: Request, res: Response, next: NextFunction) {
const apiKeyHeader = req.headers['x-api-key'];
const apiKey = process.env.API_KEY; // aus ConfigService analog ladbar
if (!apiKeyHeader || apiKeyHeader !== apiKey) {
throw new UnauthorizedException('Invalid API Key');
}
next();
}
}Diese Middleware kannst du in main.ts registrieren oder im AppModule via app.use(...). Sie prüft bei jeder Anfrage, ob ein korrekter Key mitgeschickt wurde.
JWT Auth (fortgeschrittener): NestJS bietet mit Passport.js Integration einen robusten Weg, JWT einzusetzen. Du würdest ein Auth-Module erstellen, eine JWT-Strategy definieren, die den Authorization-Header ausliest und validiert und per @UseGuards(JwtAuthGuard) deinen Controller schützen. Für dieses Tutorial nehmen wir aber an, dass entweder ein statischer Key genutzt wird oder du es in einem geschützten Umfeld einsetzt. Details zu JWT sprengen hier den Rahmen, aber falls du Benutzerkonten hast, ist das der Weg.
Wichtig für beide Fälle ist, dass Secrets niemals im Code hartkodiert werden. Wir haben bereits gesehen, wie man den OpenAI API Key in .env legt und via ConfigService lädt. Genauso machen wir es mit dem eigenen API-Schlüssel oder JWT-Secret. Zum Beispiel:
OPENAI_API_KEY=sk-... (dein OpenAI Key)
API_KEY=12345-abcde (dein eigener API-Schlüssel für Clients)
JWT_SECRET=einGeheimnis (Secret für JWT Signierung)NestJS’s ConfigModule stellt process.env[...] überall bereit oder du nutzt configService.get('API_KEY'). So bleiben all deine sensiblen Zugangsdaten aus dem Quellcode raus. Achte darauf, .env in deiner .gitignore zu haben, damit nichts versehentlich ins Repository gelangt.
Config organisieren: Für größere Projekte kann man die Konfiguration in separate Dateien auslagern und im ConfigModule laden, aber für unser Vorhaben reicht die .env Lösung. Denk nur daran, beim Deployment diese Umgebungsvariablen entsprechend zu setzen (dazu später mehr).
Mit Authentifizierung haben wir jetzt verhindert, dass Unbefugte unsere Schnittstelle nutzen. Wenn du lokal entwickelst und testest, kannst du diese Sicherheitsmechanismen auch zunächst deaktivieren, aber vor einem öffentlichen Deployment unbedingt einschalten!
Streaming-Responses & Fehlerbehandlung
Eine coole Verbesserung unseres Backends ist das Streaming der Antworten. Standardmäßig wartet der Client, bis ChatGPT die komplette Antwort erzeugt hat und bekommt dann den gesamten Text auf einmal. Mit Streaming kann man dem Nutzer aber bereits Stück für Stück Text anzeigen, während die KI noch generiert. Das fühlt sich viel reaktiver an (man kennt es aus der ChatGPT-Weboberfläche, wo die Antwort Wort für Wort erscheint).
Wie implementiert man Streaming? Die OpenAI-API bietet dafür einen Parameter stream: true. Allerdings liefert der OpenAI Node-Client dann einen Stream (einen Datenstrom), den wir verarbeiten müssen. Es gibt zwei gängige Ansätze:
Server-Sent Events (SSE): NestJS unterstützt SSE out-of-the-box. Du kannst im Controller anstelle von @Post() z.B. @Sse() verwenden und einen Observable zurückgeben. In deinem Service würdest du die Stream-Daten von OpenAI häppchenweise auslesen und als Events mittels observer.next(data) senden. Der Client (Browser) kann per EventSource diese Events empfangen und live anzeigen.
HTTP-Chunked Streaming: Alternativ kannst du den low-level HTTP-Response nutzen. Wenn du im NestJS-Controller das @Res() Response-Objekt injizierst (von Express), könntest du res.write(chunk) in einer Schleife aufrufen, während du den OpenAI-Stream liest und am Ende res.end(). Das erfordert etwas Handarbeit, ist aber machbar.
Für Anfänger ist SSE etwas einfacher, da Nest die verkapselte Observable handhabt. Ein minimalistisches Beispiel könnte so aussehen:
// im ChatService, pseudo-code:
async streamAnswer(prompt: string): Promise<AsyncIterable<string>> {
const response= await this.openai.responses.create(
{
model: 'gpt-5-nano',
input: prompt,
stream: true // eventuell nötig, je nach Client-Lib
}
);
// response ist ein Stream/AsyncIterable
return response.output_text; // gibt einen async iterator zurück
}
// im ChatController
import { Sse } from '@nestjs/common';
import { Observable } from 'rxjs';
@Sse('chat-stream')
streamChat(@Query('prompt') prompt: string): Observable<MessageEvent> {
return this.chatService.streamAnswer(prompt);
}Hier haben wir einen SSE-Endpunkt GET /chat/chat-stream?prompt=.... Der Service liefert ein AsyncIterable oder Observable zurück. In der echten Implementierung müsstest du aus dem OpenAI-Stream einzelne Nachrichten extrahieren (meist kommen JSON-Stücke, die du parsen kannst). Jeden Teil sendest du dann mit observer.next({ data: chunkContent }). Der Client bekommt so mehrere Events, bis die Antwort komplett ist.
Hinweis: Streaming ist ein fortgeschrittenes Feature. Wenn es dich überfordert, kannst du es zunächst überspringen. Deine API funktioniert auch ohne Streaming einwandfrei, nur dass der Nutzer eben warten muss, bis die gesamte Antwort da ist. SSE erfordert außerdem einen passenden Client, wie z.B. im Browser mit JavaScript new EventSource('/chat/chat-stream?prompt=Hallo') oder du implementierst es im Frontend.
Kommen wir zur Fehlerbehandlung. Der Aufruf der OpenAI-API kann Fehlermeldungen werfen, z.B. wenn dein API-Key fehlt/ungültig ist oder du die Rate Limit überschreitest, oder die Eingabe gegen Richtlinien verstößt. Wir sollten diese Fehler abfangen, damit unser Server nicht einfach mit Status 500 abstürzt.
Im ChatService kannst du den Aufruf mit try/catch umgeben:
async generateAnswer(prompt: string): Promise<string> {
try {
const response = await this.openai.responses.create({ ... });
return response.output_text || '';
} catch (error) {
// Fehler auswerten und umwandeln
if (error.response) {
// OpenAI liefert Fehler mit Status und Message
const status = error.response.status;
const message = error.response.data?.error?.message || 'Unbekannter Fehler';
// Je nach Fehler einen entsprechenden HTTP-Fehler werfen
if (status === 401) {
throw new UnauthorizedException('OpenAI API Key ungültig oder abgelehnt');
} else if (status === 429) {
throw new TooManyRequestsException('Rate Limit erreicht, bitte später erneut versuchen');
} else {
throw new InternalServerErrorException('Fehler beim AI-Service: ' + message);
}
} else {
// Kein Response-Objekt, möglicherweise Netzwerkausfall
throw new InternalServerErrorException('Keine Verbindung zur OpenAI API');
}
}
}NestJS bietet viele vordefinierte Exceptions (UnauthorizedException, BadRequestException, InternalServerErrorException, etc.), die automatisch zu passenden HTTP-Statuscodes führen. Indem wir spezifische Fehler als solche Exceptions werfen, bekommt der Client sinnvolle Antworten. Zum Beispiel: Wenn OpenAI 429 (Too Many Requests) meldet, reichen wir das als 429 an unseren Client weiter mit einer kurzen Erklärung.
Zusätzlich kannst du einen Global Exception Filter schreiben oder den integrierten Logger nutzen, um Fehler zu protokollieren. Gerade bei der Entwicklung ist es hilfreich, alle Fehler etwa mit console.error(error) (oder dem Nest-Logger) auszugeben, um die Ursache zu finden.
Observability (Req IDs, Tracing, Metrics)
In produktiven Anwendungen wirst du früher oder später Observability einrichten wollen, ein Sammelbegriff für Nachvollziehbarkeit und Monitoring deines Systems. Drei wichtige Punkte sind Request-IDs, Tracing und Metriken. Hier ein kurzer Überblick:
Request IDs: Es ist praktisch, jeder Anfrage eine eindeutige ID zu geben. Damit kannst du in den Logs eine bestimmte Anfrage über alle Logs hinweg verfolgen. NestJS lässt dich eigene Middleware einbinden. Du könntest z.B. beim Eingang einer Anfrage eine UUID generieren und sie im Request Objekt (oder als HTTP-Header) speichern. Mit einem Logging-Interceptor kann diese ID dann bei jedem Logeintrag mit ausgegeben werden. So siehst du genau, welche Log-Meldungen zu welcher Anfrage gehören. Einige Logging-Libraries wie pino oder winston kann man in Nest integrieren, um automatisch Request-IDs zu handhaben. Für den Anfang kannst du aber auch einfach per Middleware eine X-Request-ID vergeben und in der Response zurückgeben.
Tracing: Geht noch tiefer als Request-IDs. Mit verteiltem Tracing (z.B. via OpenTelemetry) kannst du messen, wie lange jeder Schritt einer Anfrage vom Empfang bis zur Antwort dauert, inkl. Unteraufrufe wie die Kommunikation mit OpenAI. Dies erfordert etwas Setup (es gibt ein @nestjs/terminus Paket für Healthchecks und OpenTelemetry oder du nutzt APM-Tools wie Jaeger, Zipkin, Datadog). Für unser Tutorial reicht das Bewusstsein: Wenn dein ChatGPT-Backend größer wird oder Teil einer Microservice-Landschaft ist, lohnt es sich, Tracing einzuführen, um Performanceprobleme aufzudecken.
Metriken: Hierunter fallen Zahlen, die das Verhalten deines Dienstes quantifizieren. Zum Beispiel die Anzahl der Anfragen pro Zeitraum, durchschnittliche Antwortzeit, Auslastung, Fehlerquote usw. NestJS kann z.B. Prometheus-Unterstützung bekommen (mit Libraries, die einen /metrics Endpoint bereitstellen). Damit könntest du z.B. messen, wie viele Chat-Anfragen gestellt wurden oder wie oft der Rate Limit gegriffen hat. Einfache Metriken kannst du auch manuell loggen oder mit einem Monitoring-Service sammeln. Für den Start muss man nicht alles haben, aber achte zumindest darauf, grundlegende Daten zu sammeln (z.B. simple Logs oder Zähler), um einen Überblick zu behalten.
Logging: Nicht zu vergessen, Logging allgemein ist Teil der Observability. NestJS hat einen eingebauten Logger (console.log tut’s im Zweifel auch in kleinerem Rahmen). Logge wichtige Ereignisse, wie z.B. eingehende Anfrage (vielleicht mitsamt Prompt, außer du willst das aus Datenschutz vermeiden), Antworten (oder zumindest die Tatsache, dass eine Antwort kam und wie groß sie war), Fehler mit Stacktrace, etc. Später kannst du Logs an Systeme wie Elasticsearch/Kibana oder CloudWatch schicken, um sie komfortabel zu durchsuchen.
Als Fazit dieses Abschnitts: Während wir unser ChatGPT-Backend bauen, ist es gut, von Anfang an Transparenz einzuplanen. So kannst du besser reagieren, wenn etwas schief läuft oder optimiert werden muss. Für unsere einfache Tutorial-Anwendung genügt es aber, sich bewusst zu sein, dass diese Mechanismen existieren, denn die vollständige Implementierung würde den Rahmen sprengen.
Deployment
Du hast jetzt ein funktionierendes ChatGPT-Backend mit NestJS gebaut. Der letzte Schritt ist das Deployment. Je nach deinen Anforderungen gibt es viele Möglichkeiten:
Eigenen Server/VPS: Du kannst einen Docker-Container auf einem eigenen Server ausrollen (z.B. via SSH und Docker CLI, oder mit Docker Compose). Stelle sicher, dass Port 3000 geöffnet ist oder mappe ihn auf 80/443 hinter einem Proxy.
Cloud-Services: Plattformen wie Heroku, Render, Railway oder Fly.io können Node-Apps oder Docker-Container direkt deployen. Auch AWS (Elastic Beanstalk, ECS, etc.), GCP (Cloud Run) oder Azure bieten simple Wege, Container zu betreiben. Für den Einstieg sind Services wie Render oder Heroku beliebt, da man wenig Infrastrukturkenntnis braucht, dort kannst du meist direkt ein GitHub-Repo verbinden und das Deployment passiert automatisch.
Kubernetes: In größeren Projekten werden Container oft auf Kubernetes betrieben. Das sprengt aber definitiv unseren Rahmen hier. Mit einem Docker-Image hättest du aber auch dafür eine Einheit, die du deployen könntest.
Wichtig ist, dass du im Deployment-Umfeld wieder die notwendigen Environment Variables setzt (OpenAI-Key, ggf. API-Key/JWT-Secret). Lege diese in den Settings des Cloud-Dienstes sicher ab, anstatt sie ins Repo zu schreiben.
Nach Deployment sollte dein ChatGPT-Backend von überall erreichbar sein (sofern vorgesehen), zum Beispiel könnte eine Frontend-App nun Requests an https://deine-domain.tld/chat schicken und unser NestJS-Server vermittelt zum OpenAI-Service.
Vergiss nicht, auch in Produktion Logging und Monitoring im Blick zu haben. Anfangs reicht vielleicht ein einfaches Logging in die Konsole (die man z.B. bei Heroku abrufen kann). Später kannst du Tools hinzufügen, um die Nutzung und Performance zu überwachen.
Nächste Schritte
Geschafft! Du hast einen Überblick erhalten, wie man ein eigenes ChatGPT-Backend mit NestJS und OpenAI erstellt, von der Architektur über Authentifizierung bis hin zu Deployment. Dieses Tutorial sollte dir den Einstieg erleichtern, auch ohne tiefes TypeScript-Wissen.
Experimentiere ruhig weiter: Füge neue Features hinzu, verbinde ein Frontend oder erweitere den Service um Funktionen wie Konversationsverlauf, differenzierte Modelle (z.B. GPT-4) oder ein kleines Interface zur Moderation der Prompts.
Ich hoffe, dieses NestJS OpenAI Tutorial hat dir gezeigt, dass man ein ChatGPT-Backend selber bauen kann und zwar mit überschaubarem Aufwand. Viel Erfolg beim Coden und Ausprobieren! Bleib neugierig und hab Spaß beim Entwickeln deines eigenen KI-Backends. 🚀
Kommentare
Bitte melde dich an, um einen Kommentar zu schreiben.